
Master Zap Message Board - Master Zap YOUTUBE Master Zap BLOG Master Zap mental ray BLOG
Please use "my" URL http://www.Master-Zap.com when linking!
|
Master Zap Message Board - Master Zap YOUTUBE Master Zap BLOG Master Zap mental ray BLOG Please use "my" URL http://www.Master-Zap.com when linking! |
||||||||||||||||||||||
| This should no longer be considered as a "proposal for behavior in VRML". This process has gone a slightly different way nowdays, and I have not had time to update this. However, what is still interesting here, is my ideas about multiuser spaces, about "engines" and "brains", a duality that is necessary for making a shared virtual universe real..... |
| I believe this message to be truly interesting and to actually contain useful insights. I apologize in advance for it's size, but I couldn't make it much smaller.... |
| This icon is used to mark new stuff added, or otherwize changed since last revision. Click on it to move to the next new item. |
Therefore I suggest the following division: The Level 0/1 behaviours are the "engines" (to borrow a term from Open Inventor). Level 2/3 behaviours are the "brain". In this text I will mostly talk about the distinction between "engine" and "brain".
An engine script doesn't respond to outside events. (The brain does.) It only responds to time, and it's initial parameters. The brain provides these initial parameters, and may modify them, or replace the engine script completely.
![]() The engine script is called each frame by the renderer, to query the position of the
objects in the scene. The script should avoid storing information from one invokation
to the next. It should not rely on variables, other than the initial parameters.
An engine must be written in such a way that it can be passed a time T, and the
enginge should know what to do at that time.
The engine script is called each frame by the renderer, to query the position of the
objects in the scene. The script should avoid storing information from one invokation
to the next. It should not rely on variables, other than the initial parameters.
An engine must be written in such a way that it can be passed a time T, and the
enginge should know what to do at that time.
However, an engine can be of any complexity. It can actually borrow a lot from Bernies level 2 behaviours! We could create an engine for "Run to the tree and climb up". Actually, the more complex the engines are, the less network traffic will be generated!
To: Object (squirrel#7):
Execute function "WalkTo"
Start time: 1995-10-01 14:31:09.55
Duration: 5 seconds
Parameters:
InitialPos = 30.0, 25.3, 11.5
Goal = 50.0, 30.0, 11.5
This will tell the squirrel engine (loaded thru a WWWScript node) to execute the function "WalkTo".
The parameters "InitialPos" and "Goal" are two input-parameters to the "WalkTo" function.| The representation would naturally not be text, but much more compact. E.g. the function name could be an enumerator giving that functions ordinal in the squirrel engine script. |
Since the packet contains the initial timestamp, a small latency in the net is hardly noticable. As soon as the packet arrives at any host running the simulation, the squirrel will be in sync, because the engine is a function of time, and can easily be "jumped into". And when the end-time arrives, it will stop.
But what if the squirrel "brain" detects a wolf after two of those five seconds? No problem. A new packet is sent:
To: Object (squirrel#7): Execute function "Flee" Start time: 1995-10-01 14:31:12.04 Duration:Now a new "execute script" packet is sent. In this case a new function (Flee) in the same file is used. The old engine is overriden with the new one (an engine script which is "in progress" is overridden by a new engine script with a timestamp within the timespan of the currently executing script.) An indefinite "fleeing" behaviour will be initiated. Hopefully (for the squirrel) the brain will eventually decide to stop fleeing (and get some rest) and send a new override packet with a stop message...Parameters: InitialPos = 42.0, 27.5, 11.5 DirectionVector = -12.0, -5.0, 0.0
| The "WalkTo" and "Flee" scripts are in this case in one file. They could alse be two completely different files. It could also be one script with a different parameter (WhatToDo="walk" or "flee"). The important thing is that the brain supplies the correct parameters for a particular script. The brain must know the engines interface. |
| Here's my little blockbuster.... :-) |
The "brain" could easily forsee the future of a simple deterministic behaviour. A ball dropping to the floor will bounce. A vase will shatter. Therefore the brain is allowed to post FUTURE messages with a timestamp of the FUTURE.
Allowing looks into the forseable future, can inprove remote responsivness greatly. The vase will shatter and the ball will bounce at the same instant for all viewers.
Of course the bounce or the shatter could have been built into a complex fall-and-bounce or fall-and-shatter "engine" behaviours. As said before, these can be arbitrarily complex. But this is just an example.
In a complex case, the brain could forsee that object A and object B will collide in three seconds, and post a forsight message about the resulting bounce.
![]() This means that for each virtual object, there is a sort of "message queue", which can store
these "future time-stamped" events, and sequentially execute them as their respective start-time arrives.
This means that for each virtual object, there is a sort of "message queue", which can store
these "future time-stamped" events, and sequentially execute them as their respective start-time arrives.
Even in the squirrel case, these future messages can be used without sacrificing realism. Lets say the brain detects the wolf. So the brain posts a packet saying "Start fleeing in 2 seconds". This gives us the following "features":
If it does this, it posts another future packet, that has an earlier timestamp than the "Flee"
packet, plus an override flag. This flag essentially means "when a packet of this type
arrives, flush any events with later times from the queue.
But, In my opinion, there are two kinds of "brains":
The scripted brains, on the other hand, can reside anywhere! And, IMHO, the scripted
brains should run in the host machine of the first user who causes that object to be loaded.
If this user loggs off while others are still "there", a handover of the "brain" must be done
to somebody else. Another important feature is
that the "brain" can also decide for itself to "become owned" by another user.
Why do I want this to happen, you may ask?
Well, I am thinking of two things:
The Brain
So, where is the brain? As Bernie notes ("behav.html:Why not level 2?"), the brain must run
in exactly one place. I couldn't agree more.
Obviously physical location (i.e. the IP adress) of a "special" brain is important.
The "special" brain exists somewhere on the net. It is sends and receives messages, and
governs the object.
Objects and Brains
This is how I envision an object inclusion in VRML:
Def Squirrel {
WWWInline geometry "http://www.xyz/~zap/squirrel.vrml"
WWWScript engine "http://www.xyz/~zap/squirreng.vrbl#SitNWait"
WWWScript brain "http://www.xyz/~zap/squirrel.vrbl"
}
In the above example we inline the geometry in the file "squirrel.vrml". The first engine
to be applied to the squirrel is in squirreng.vrbl, the function "SitNWait", with the
default parameters for that engine.
(Loading no engine would be legal, and probably the normal thing to do).![]() The brain is a scripted brain: squirrel.vrbl. In this case it is loaded on the same spot as the
engine. This automatically gives the brain the same scope as the engine.
The brain could have been loaded on a higher level.
The brain is a scripted brain: squirrel.vrbl. In this case it is loaded on the same spot as the
engine. This automatically gives the brain the same scope as the engine.
The brain could have been loaded on a higher level.
| For language choices, I would suggest ATLAST (a Forth-like language). It has the advantages in simplicity, and being in the Public Domain. |
Def MyAvatar {
WWWInline geometry "http://www.xyz/~zap/me.vrml"
WWWScript engine "http://www.xyz/~zap/me.vrbl"
WWWScript brainlink "http://www.xyz:9876/~zap/"
}
This syntax means that the brain isn't in a file. The brain is already there,
running, out on the net. The port is where the messages go, and where they
come from. This is a special brain (because it is my brain!!) so it can't be
handed over. This object wouldn't work if I wasn't connected to the net (or
at least could reach www.xyz in this case).
![]() The VRML specification specifically states that a browser isn't required to keep the scene
graph model in memory. However, the key issue when connecting the engine to the geometry, is
that the scene graph must be retained, but only for the modifyable objects.
The VRML specification specifically states that a browser isn't required to keep the scene
graph model in memory. However, the key issue when connecting the engine to the geometry, is
that the scene graph must be retained, but only for the modifyable objects.
Here is a proposal for how it might look:
DEF Squirrel DYNAMIC Separator {
# Load squirrel behaviour script
WWWScript engine "http://www.lysator.liu.se/~zap/squirrel.vrbl"
WWWScript brain "http://www.lysator.liu.se/~zap/squirrel.vrbl"
DYNAMIC Transform "pos" {
translation 0 0 0 # Position the squirrel
}
# Squirrel body
Cube {
width 10
height 20
depth 10
}
DYNAMIC Separator "rgt_thigh" {
DYNAMIC Transform "pos" {
translation . . .
rotation . . .
}
# Squirrel's RIGHT thigh
Cube {
width 2
height 2
depth 15
}
DYNAMIC Separator "ankle" {
DYNAMIC Transform "pos" {
translation . . .
rotation . . .
}
# Squirrel's ankle
Cube {
width 2
height 2
depth 15
}
}
}
DYNAMIC Separator "left_thigh" {
DYNAMIC Transform "pos" {
translation . . .
rotation . . .
}
# Squirrel's LEFT thigh
Cube {
width 2
height 2
depth 15
}
DYNAMIC Separator "ankle" {
DYNAMIC Transform "pos" {
translation . . .
rotation . . .
}
# Squirrel's ankle
Cube {
width 2
height 2
depth 15
}
}
}
DYNAMIC Separator "head" {
DYNAMIC Transform "pos" {
translation . . .
}
DYNAMIC Material "blush" {
diffusecolor 0.6 0.4 0.2
}
DYNAMIC Coordinate3 "mesh" {
point [-2 0 -2, -2 0 2, 2 0 2, . . . ]
}
IndexedFaceSet {
coordIndex [ 0, 1, 2, . . . ]
}
}
}
The above changes have the following meaning:
DYNAMIC nodename "refferable name" { ....
Some nodes can be defined as DYNAMIC. As you do that, you give them a refferable
name. This is used by the behaviour engine to modify the position of the object.If, for instance, we set attributes defining the leg-length and allowed turning-angles for joints in the squirrel, we could use a standard "walk" model for walking without having to write our own squirrel-walk. We could just pick one off the shelf, adopt is't naming scheme, set up the attributes to make the "walk" behaviour behave, and off it goes.
By this method, lots of people will start writing useful behaviours. With the correct division between attributes (defined in the model) and their use (in the engines), reusability is ensured.
Today most worlds are small, because of the rendering power of the contemporary machines. A single .vrml file wouldn't fit much more than five people before the RENDERING is bogged down anyway, so I suggest:
For now, we igonre this issue. (Using the discussion below, doing so now is sort of "safe"). Why? Well, if the current shape of vrml worlds will set the standard, we will not be building "huge, seamless worlds". We are building little islands-with-links. Therefore, IMHO, the ZOI == the top level vrml world.
| Of course I would love it if we could add WWWAnchors for user position and direction-of-motion. That way we could walk-thru-doors and flu-thru-windows instead of this unintuive "click on the door to go elswhere" of today. |
Very Complex "Engines" reduce net traffic: If the "walking" of a person is accomplished by a spline interpolated table of samples of real walking people's legjoint rotation patterns, and the "walking" behaviour includes such complex "parameters" as "walk to this spot following a spline with these control points at these points in time", no net traffic needs to happen during the entire, highly realistic walk! Compare that to transferring the angle of each joint each frame.......
Each object created in the world would receive it's own instance identifier (e.g. IP adress of creator + index no). This is used througout to reference this object.
With a bit of though, you can see that this approach scales nicely too. Assume there is a server. This is the same scenario again, now WITH server:
WWWServer {
name = "vrtp://vr.wired.com:9876/this_world"
}
This sever is contacted by the browser. The browser sends the "what's up
dude?" message to the server. The server sends:
But lets assume 2093 people log in. The server may decide to move to some broadcasting mode. It sends out a list of IP adresses to send to: Only the servers IP itself.
So when Art logs in, he is never informed about Charlies IP adress (or any other of the 2093 people there). He never directly sends packets to Art. He sends them to everybody-but-himself on the list (which is, only the server).
The server then starts to broadcast the stuff instead......
Similarly, the server could pass a multicast adress as the one to be used...
Here is an overview of the interfaces:
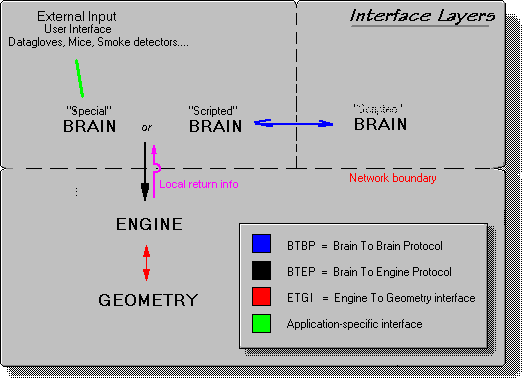
The engine should also support a few standard return functions. These are called directly by the brain to the local copy of the engine. These should include things like:
These functions are standardized because they are available for any brain. E.g. when the Wolf wants to know where the squirrel is, the wolfs brain can query the local copy of the squirrel directly.
| Naturally it could ask the squirrels brain, which would give a more accurate position of the squirrel, but that information would be subject to lag. Asking the local squirrel might be incorrect (because of a pending update packet subject to lag) but doesn't have any lag at all. It is up to the application to decide which method to use for position testing. For simple proximity testing, asking the local copy of an object is encouraged, since it saves bandwidth. |

