


``Computer security'' is a very broad area. One large reference work in the area, the Computer Security Reference Book, features 66 chapters in some 900 pages, but each chapter serves only to introduce a topic [JH92]. A reference work of this kind covers all aspects of the security process and takes into consideration many areas of application.
Most of what can be said about security in general also applies to computer security. In traditional security work, threats and risk are often physical in nature: theft, sabotage, fire, flooding, breakdowns, etc. These apply of course to computers as well. However, the area of computer security is special in that it also must deal with protecting information stored in a system.
What, then, can put information in our computer systems at risk? Without saying anything about what might, or might not, constitute harm to a specific organization, it is still possible to identify a number of categories of possible threats to an organization using computers. Threats to information turn into risks when an organization begins to become dependent on computer applications and information processed in computers.
To get a grip on these threats, we can start by looking at what is threatened. A coarse categorization results in three main groups: threats to availability, threats to confidentiality, and threats to data integrity.
Availability means that applications and information are available when they are needed. The more dependent an organization is on its information system, the more severe are the consequences of denied availability. Availability can be denied in many ways. Someone might steal a computer, the computer hall might burn down or get flooded, electricity might fail, networks can become over-congested, software might fail, file servers might go down, hard disks can crash, etc.
A threat to confidentiality is present whenever harm may come from computerized information being disclosed to an outside party. Here, harm might be to personal integrity, business, national security, or other items. What is defined as an outside party may also vary. It could be anyone but a single person, anyone outside a board of directors, anyone outside an organization, or even a specific set of individuals.
We touch finally upon threats to data integrity. Today many organizations rely heavily on computer information systems to provide data for making important decisions. Implicit here is a trust in that the information stored is correct. This is not, however, always the case. Again, depending on specific circumstances, the effects of using inconsistent or incorrect information may range from losing pennies to having space rockets take the wrong turn.
In addition to the direct consequences of threats of various kinds, there are in most cases also secondary consequences in the form of extra work and expenses to recover from the direct consequences.
Figure 2.2: Threats categories where access control can help.
We have already categorized threats according to the target of the threats. We can also look at the origin of a threat. We can, for instance, divide into one group those threats that come from nature and natural events, fire, floods, mechanical failures, etc., and into another group threats arising from the actions of individuals. This latter group can be further divided into threats where people cause harm inadvertently and where people act with the malicious intent to cause harm. If we combine this ``by whom'' categorization with the earlier one based on ``what'', we get a matrix containing nine types of threats, as shown in figure 2.2. Given these nine categories we can examine countermeasures to see which parts of the matrix they cover. To achieve true security we would have to cover all categories completely. To exemplify, in the figure we have sketched an area that roughly corresponds to the protection offered by access control. Other areas require other measures. For instance, to cover area 1, threats to availability of natural origin, countermeasures could be to place computer installations on high ground, having smoke detectors, and fireproof walls.
Today, most computer workplaces have some form of network connecting them to other computers, locally or globally. From at first having been mainly a way of pooling expensive resources, such as hard disks and printers, the communication services offered by the interconnecting network are more and more used to letting applications and users interact with each other. The fantastic growth explosion of the Internet shows there is an enormous potential for computer communication. The Internet explosion and the advent of the World Wide Web also show that existing technologies often are put to new uses, not originally anticipated.
In this section we look at distributed systems, and at security issues related to them. Before we can do this we need some conception about distributed systems.
When looking for examples of systems that are distributed we can immediately see that there are many kinds of systems that in one way or another can make claim to the title. Just to mention some, there are:
Taking these examples together, we can see that much of what is sometimes called the ``IT revolution'' could only have happened thanks to the advent of computer networks and various forms of distributed applications.
Networks and distribution have brought many advantages and new possibilities. Unfortunately, when we make our systems distributed, we also make them more vulnerable.
It is only natural that when we make use of new technologies, or old technologies in new ways, new aspects of old issues will emerge. To illustrate some security aspects of distribution, figure 2.3 elaborates on figure 2.2 by giving some examples of new threats introduced by distribution.
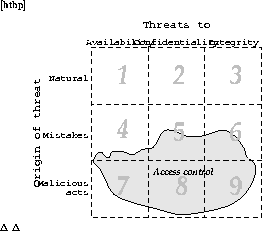
Figure 2.3: Threats introduced by distribution.
The figure shows an array of different possible threats. Natural events such as fire and flood may sever a communications link. A communications link subjected to electrical and magnetic fields might introduce erroneous bits in the data stream of a message, as can faulty contacts and other mechanical damage. A link can also be severed by mistake in many ways or one cable connector can be mistaken for another.
Distribution that is transparent might cause a user to inadvertently send sensitive data over an unsecured network, a transfer that would not happen if the user were aware of the risk. Another mistake would be for a user to store files locally instead of on a network drive, with the result that these files are not backed up.
An assailant may try to disrupt traffic among communicating parties in several ways. The actual link could be destroyed or the recipient can be flooded with messages making it impossible for legitimate messages to get through. A communications link gives ample opportunity for an intruder to eavesdrop on data sent over the link. This is especially true in public networks where it is relatively easy to write applications that listen for, and logs copies of, packets destined for some specific recipient or coming from some specific originator. An intruder might also insert himself between two communicating entities and attempt to alter information that is sent between the parties. He might also try to fake messages, pretending to be a legitimate originator.